# 슈퍼 타입과 서브 타입
Extended ER 이라고도 부른다.
공통인 부분을 슈퍼 타입, 상속받아 다른 엔터티와 차이가 있는 부분은 서브 타입이라고 함
각각의 속성을 할당해서 수평 분할을 하는 모델을 슈퍼/서브 타입 데이터 모델이라고 함
슈퍼/서브 타입 데이터 모델을 통해..
- 정확하게 업무를 표현할 수 있고
- 물리적 모델링 시 선택의 폭을 넓힐 수 있다.
- 하지만, 일정한 기준으로 변환해한다 → 아니라면 성능저하의 위험이 있다
▶ 슈퍼 / 서브 타입 데이터 모델의 변환 기술
변환 기준: 데이터 양, 트랜잭션 유형
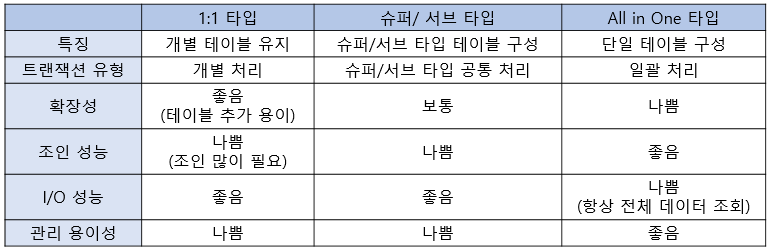
- 1:1 타입: 개별로 발생되는 트랜잭션에 대해서는 개별 테이블로 구성
- 슈퍼/서브 타입: 슈퍼/서브 타입에 대해 발생되는 트랜잭션에 대해서는 슈퍼/서브 타입 테이블로 구성
- All in One 타입: 전체를 하나로 묶어 트랜잭션이 발생할 때는 하나의 테이블로 구성
# PK / FK 칼럼 순서 조절을 통한 성능 향상
여러 개의 속성이 하나의 인덱스로 구성되어 있을 때 앞쪽에 위치한 속성의 값이 비교자로 있어야 효율이 좋다
= 앞쪽에 위치한 속성의 값이 가급적 '=' 아니면 'BETWEEN', '<>'가 들어와야 함
즉, 여러 조건이 있을 때는 등호 조건이 걸리는 칼럼을 앞으로
# 인덱스 특성을 고려한 DB 성능 향상
물리적인 테이블에 FK 제약을 걸어 인덱스 생성
'공부 > SQLD' 카테고리의 다른 글
| [SQLD] 관계형 DB (0) | 2023.10.30 |
|---|---|
| [SQLD] 분산 DB 데이터에 따른 성능 (0) | 2023.10.26 |
| [SQLD] 대용량 데이터에 따른 성능 (0) | 2023.10.22 |
| [SQLD]★반정규화★ (0) | 2023.10.22 |
| [SQLD] ★정규화★와 성능 (0) | 2023.10.18 |

댓글